
Reflective Prompt Evolution with DSPy: GEPA Insights for Modular AI Systems
From RL to Reflective Prompt Optimization: The GEPA Breakthrough

In the quest to adapt large language models (LLMs) to complex tasks, traditional reinforcement learning (RL) approaches have shown both promise and pain. Methods like Group Relative Policy Optimization (GRPO) can eventually teach an AI agent a new task, but often at the cost of thousands of trial-and-error rollouts . The recently introduced GEPA (Genetic-Pareto) prompt optimization paradigm turns this approach on its head by leveraging language itself as the learning medium. Instead of relying on sparse numeric rewards, GEPA uses natural language reflection on the model’s reasoning and outputs to guide improvement . In other words, the AI agent becomes its own coach: after each attempt, it analyzes what went wrong in plain English, then refines its prompts accordingly.
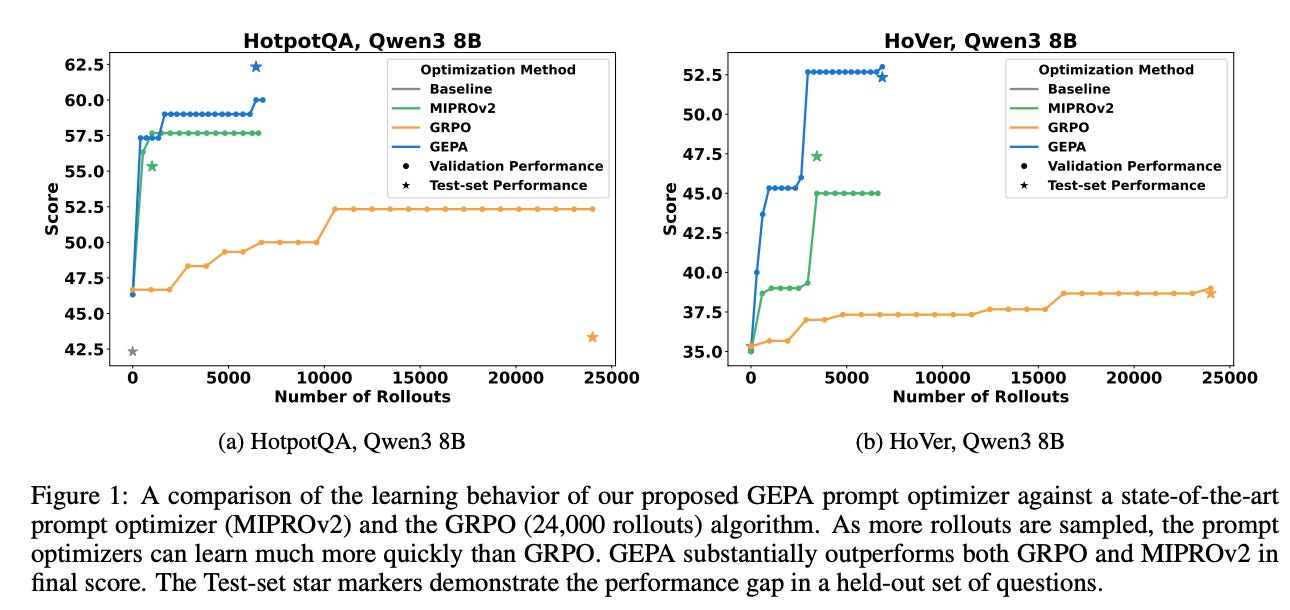
This reflective prompt evolution strategy has yielded striking results. GEPA can transform just a handful of model executions into significant quality gains, far beyond what RL achieves with the same budget . Across multiple tasks, GEPA outperformed a strong RL baseline (GRPO) by an average of 10% (up to 20% on some tasks), all while using up to 35× fewer trials . It even beat a leading prompt-tuning method (MIPROv2) by over 10% on the same tasks . The secret sauce is a natural language feedback loop: GEPA’s algorithm samples full reasoning trajectories (including any tool calls or intermediate steps an agent took) and has the model reflect in words on those trajectories to diagnose errors, propose better prompt instructions, and combine the best ideas from multiple attempts . By collecting a Pareto frontier of diverse successful strategies, GEPA merges complementary solutions—much like an evolutionary algorithm recombining genes—to produce an optimized prompt that balances trade-offs (accuracy, efficiency, etc.) . This genetic-Pareto optimization means no single attempt needs to be perfect; different partial successes are integrated into a new prompt that is better all-around.
For a concrete image, imagine a multi-hop question-answering agent confronted with a complex query: “Which author who won the Nobel Prize in Literature also wrote a play that inspired a famous opera by Verdi?” A naive agent might retrieve information about the author and the opera but fail to connect them correctly, yielding an incomplete answer. A GEPA-style approach would have the agent review its own reasoning step-by-step: perhaps noting in natural language, “I found the Nobel Prize-winning author and the opera, but I didn’t verify if the opera was based on that author’s play.” This reflection would lead it to update its prompting strategy—maybe by adding an instruction to double-check the connection between the play and the opera. By iterating in this way (diagnosing errors and refining the prompt), the agent quickly learns a more effective multi-step strategy without ever adjusting the underlying model’s weights. GEPA’s core insight is that language is a rich teacher: an AI system can learn high-level rules and strategies from its own explanations and critiques, achieving sample-efficient improvement that brute-force RL struggles to match .
DSPy – A Framework for Self-Optimizing Prompt Strategies
Enter DSPy, an open-source framework from Stanford designed to bring this kind of adaptive prompt optimization into everyday development. DSPy is described as “the framework for programming—rather than prompting—language models.” It lets AI practitioners write modular, declarative code to define an LLM-driven workflow, and then automatically tunes the prompts and behavior of that workflow for better performance. In essence, DSPy acts like a compiler for prompt-based AI programs . You specify what you want the AI to do (via a task signature and modular components), and DSPy figures out how to prompt the LLM to do it most effectively, through a process of compilation and optimization.
Some standout features of DSPy include :
Declarative Task Definition: You describe the task in terms of inputs and outputs (a Signature), not by hand-crafting a giant prompt. For example, you might declare a signature question -> answer or a more complex one with multiple fields like document + query -> summary . This is analogous to defining a function’s interface in code.
Modular Programs: DSPy provides building blocks called Modules that encapsulate specific prompt strategies or sub-tasks. Each module implements some logic – e.g. a Generate module for a basic prompt-completion, a ChainOfThought module for step-by-step reasoning, a ReAct module for reasoning with tool usage, or a Rerank module for selecting the best answer from candidates . These modules can be composed into multi-step pipelines, much like functions in a program, to tackle complex workflows.
Optimization-First Compilation: Perhaps most importantly, DSPy is built with the assumption that you will optimize your prompt pipeline, not just run it naively . You can compile your DSPy program with real or synthetic data, and DSPy’s optimizers (also called Teleprompters) will automatically refine the prompts, add few-shot examples, insert chain-of-thought cues, or even suggest fine-tuning if appropriate . All of this happens behind the scenes, so you spend far less time manually tweaking prompt wording. As one practitioner noted, using DSPy feels like “ceding the details and nuance of the prompt back to an LLM” – you define the high-level structure, and let DSPy handle the prompt engineering minutiae .
Crucially, DSPy’s design aligns with the multi-stage, feedback-driven philosophy exemplified by GEPA. Complex AI applications often involve multiple interacting prompts or steps – for instance, a multi-hop QA agent might have one step to retrieve information and another step to formulate the answer. Traditionally, tuning such a chain is painstaking; changing one prompt can break the others’ synergy . DSPy addresses this by treating your whole chain as a coherent program, yet isolating each step as a module that can be improved independently and in concert. The framework “abstracts away (and powerfully optimizes) the parts of these interactions that are external to your actual system design,” letting you focus on the module-level logic while it fine-tunes the prompts that glue these modules together . In practice, the same high-level DSPy program (say, a retrieval-augmented QA pipeline) can be compiled into an optimal set of prompts tailored to a specific model or context – whether that means generating multi-turn instructions for GPT-4 or crafting efficient zero-shot prompts for a smaller local model . You no longer need to maintain long, brittle prompt strings for each model; DSPy’s compiler takes care of that, akin to how a high-level programming language is compiled down to optimized machine instructions .
How DSPy Learns to Prompt (Modules and Teleprompters)
To see how DSPy might realize GEPA-like improvements, let’s break down its components most relevant to reflective prompt evolution:
Module Abstraction: Each DSPy module represents a self-contained prompt + LLM call that accomplishes one step of the task. For example, in a multi-hop QA scenario, you might have a RetrieveFacts module (which, given a question, uses an LLM or a tool to fetch relevant evidence) and an AnswerQuestion module (which forms the final answer from the question and retrieved facts). Because these modules are defined independently (with their own input/output signature and internal prompt), DSPy can target specific modules for optimization. This is very much in the spirit of GEPA’s idea of treating “any AI system containing one or more LLM prompts” as candidates for improvement . A module’s prompt is like a gene that can evolve. By encapsulating prompts in modular units, DSPy makes it easier to apply localized fixes based on feedback – e.g., if the retrieval step often misses relevant sources, you can improve just that module’s prompt without overhauling the entire pipeline. And because modules are reusable, a refined module can be plugged into other workflows as well.
Optimizers and Feedback-Driven Refinement: DSPy’s optimizers (also called compilers or teleprompters) are algorithms that automate the prompt-tuning process for your modules. Under the hood, many of these optimizers do exactly what a human prompt engineer or GEPA-style agent would do: they run the program on sample inputs, observe the outputs, compare them against desired outcomes (via metrics), and then adjust the prompts accordingly . In fact, the DSPy docs note that current optimizers can “simulate traces through your program to generate good/bad examples of each step, propose or refine instructions for each step based on past results,” among other techniques . This is a direct echo of GEPA’s reflective loop: the optimizer can look at a trace (sequence of module outputs, intermediate reasoning, tool calls, etc.) and pinpoint where the chain is faltering, then tweak the prompt or instructions at that weak link. For instance, our QA agent’s optimizer might notice that the AnswerQuestion module often ignores one of the retrieved facts, leading to incomplete answers. In response, it could adjust that module’s prompt to explicitly remind the LLM to use all provided facts, or insert a few-shot example demonstrating the combination of multiple sources. DSPy will actually carry out this change and test the new prompt to see if the metric (e.g., accuracy of the final answer) improves .
Natural Language Feedback as Metrics: One of GEPA’s key advantages is leveraging interpretable feedback instead of opaque reward signals. DSPy is built to take advantage of rich feedback as well. You can define custom metrics for your program – these could be simple numeric evaluations (like 0/1 correctness against a ground truth), but they can also involve LLM-based evaluation or heuristic checks . For example, you might use an “LLM-as-a-judge” metric that has a separate model verify whether the answer correctly addresses the question and uses the evidence provided . Or you might incorporate validation rules (say, expecting the final answer to contain a citation from each retrieved document). Such feedback mirrors the natural language critique in GEPA. Instead of a sparse reward, the optimizer has access to richer signals about why an output was good or bad. DSPy’s architecture even allows for validators in the form of assertions or suggestions within a program, where one module can check the output of another and flag issues, triggering a retry or different strategy . This kind of built-in reflective check can be seen as a simple realization of GEPA’s “critic” that analyzes the agent’s trajectory .
Compilation Pipeline and Pareto Efficiency: When you run a DSPy optimizer, it doesn’t just spit out one static prompt – it often explores many variations and might maintain several candidate solutions internally. Some optimizers (like those that do few-shot example bootstrapping or prompt search) will generate multiple prompt versions, test them, and select the best . In doing so, DSPy can implicitly perform a kind of multi-objective optimization. For instance, you might care about both accuracy and latency, or accuracy and token cost. DSPy could evaluate prompts under multiple metrics or varying conditions and then let you choose a balanced solution. This is conceptually similar to GEPA’s Pareto frontier approach, where instead of one monolithic “best” prompt, the system considers a set of promising prompts that offer different trade-offs . By combining lessons from those non-dominated attempts, you move toward a prompt that improves overall performance without severe regressions. While DSPy’s current optimizers (such as MIPROv2 or PipelineTeleprompter) typically optimize a primary metric, the framework’s flexibility means you could incorporate multi-metric evaluation. In fact, the DSPy team explicitly encourages extending the optimizer library to cover more “self-improvement” strategies, noting that most manual prompt-engineering tricks can be generalized into a DSPy optimizer . It’s not hard to imagine a future DSPy optimizer that implements the full GEPA algorithm – and thanks to DSPy’s modular design, such an optimizer could plug in and start tuning any defined program’s prompts out-of-the-box.
To illustrate, let’s revisit our multi-hop QA example in a DSPy context. We define a simple DSPy program with two modules: RetrieveFacts (perhaps using a dspy.retrieve.ColBERTv2 tool or a Generate with a prompt like “Search for facts about X”) and AnswerQuestion (using a dspy.Generate with a signature that takes the question and retrieved text and produces an answer). We provide a few training examples of questions with their correct answers (and maybe evidence passages). Now we invoke a DSPy optimizer – say, the built-in MIPROv2 or a hypothetical ReflectiveOptimizer. This optimizer runs our program on the training questions. Suppose for one question, the agent’s answer was wrong because it missed a key fact from the retrieved text. The optimizer notices the discrepancy (the metric indicates the answer is incorrect, and perhaps an LLM judge says “the answer ignored part of the question”). It then analyzes the trace: the RetrieveFacts step got relevant info, but the AnswerQuestion step’s prompt simply said “Answer the question using the provided text” and the model didn’t actually use all the text. The optimizer generates a refined prompt for AnswerQuestion, perhaps: “Using all the facts above, answer the question thoroughly.” It tests this change on that example (and others), sees the accuracy go up, and locks in the improvement. In a few such iterations, DSPy might also adjust the retrieval prompt (e.g., add an instruction to find multiple distinct sources). The end result is a compiled program where the prompts for each module have evolved to handle multi-hop questions much more reliably – effectively learning from its own mistakes in a GEPA-like fashion. All of this was automatic; as developers, we simply defined the modular pipeline and let DSPy’s reflective optimizers do the hard work of prompt tweaking.
Agentic Workflows: Multi-Step Reasoning Meets Modular Optimization
Complex AI agents – the kind that plan, reason, and use tools iteratively – stand to benefit immensely from DSPy’s approach. These agentic workflows involve multiple LLM calls and decisions that feed into each other, exactly the scenario where reflective prompt evolution shines. Amazon’s new AWS Strands Agents framework is a prime example of enabling such multi-step agent behavior. Strands Agents is an open-source SDK for building AI agents that emphasizes a model-first, minimal prompt philosophy . Instead of painstakingly scripting each step of the agent’s process, you provide: (1) a base LLM (from AWS Bedrock or elsewhere), (2) a set of tools the agent is allowed to use, and (3) a high-level natural language Prompt that describes the agent’s task and how it should behave . The heavy lifting of reasoning and deciding is left to the LLM itself – the agent dynamically figures out how to break down the problem, which tools to invoke, when to iterate, etc., all guided by the prompt and the model’s own capabilities .
Strands Agents operate via an “agentic loop,” in which the LLM plans actions, calls tools, and reflects on the results in a cycle until the task is complete . This loop (illustrated above) allows complex multi-step problem-solving without rigid workflows.
The Strands Agent loop is essentially: User request → LLM thinks (proposes an action) → LLM uses a tool or produces an intermediate output → LLM reflects on the new information → repeat as needed, then finalize an answer . It’s a powerful paradigm, allowing the agent to correct its course mid-flight. However, the quality of the agent’s decisions and reflections still depends heavily on that initial prompt (and any internal prompting pattern the agent follows). In the Strands philosophy, you try to avoid super-specific, brittle prompts – you trust the LLM to “just figure it out” with minimal guidance . In practice, though, a bit of guidance can go a long way, especially for complex tasks. This is where integrating DSPy can elevate an agentic system like Strands to the next level.
Think of the Prompt in Strands Agents as the brain of the agent. It’s typically a chunk of natural language instructions given to the model, perhaps describing the goal (e.g. “You are a research assistant. Answer the user’s question by searching the web and compiling findings.”) along with some format guidelines. If this prompt is poorly tuned, the agent might produce suboptimal plans: maybe it overuses a tool, or fails to stop when it should, or ignores part of the question. With DSPy, we can treat that prompt as an optimizable module. Rather than guessing how to word the agent instructions, we can let the system learn from experience. By plugging DSPy into the development cycle, a Strands agent can run on example tasks and receive feedback, just like our earlier pipelines. DSPy’s optimizer could, for instance, observe that the agent often forgets to use the retrieve tool for multi-hop questions, and consequently add a line to the instructions like, “If the question might require multiple facts, be sure to use the search tool to find all relevant information.” Or it might discover that the agent’s final answers are too verbose and add guidance to be more concise. Essentially, DSPy can fine-tune the agent’s persona and strategy encoded in the prompt without any manual trial-and-error. And since Strands encourages an iterative reflective loop (the LLM “reflects and iterates” during the agent’s reasoning ), a DSPy-optimized prompt can explicitly enhance that reflection phase. For example, the prompt could be evolved to include an internal checklist the agent uses when reflecting (“Did I use all available tools? Did I verify the answer?”), an idea very much inspired by GEPA’s use of a reflective critic .
An exciting part of this integration is that it requires no changes to the LLM itself. Strands Agents leverages powerful foundation models via APIs (such as GPT-4, Claude, or other Bedrock models), which developers typically cannot fine-tune in a production setting. DSPy’s method of prompt-based optimization is therefore ideal: it squeezes more performance out of the existing model by improving how we prompt and orchestrate it, rather than altering the model’s weights . This keeps things lightweight and maintainable. In a production agent, you can continuously gather logs of where the agent struggled (maybe user feedback or automated checks point out errors), convert those into a small training set, and re-compile your DSPy-enhanced Strands agent. The result is an agent that learns to handle edge cases over time through prompt adaptation, not unlike how a human would learn from mistakes by updating their approach.
Transferring GEPA’s Genetic-Pareto Boost into Agents
By integrating DSPy-optimized modules into an agentic framework like Strands, we effectively inherit GEPA-like optimization capabilities in our system. Consider a multi-hop question answering agent running on Strands: initially, it might solve questions in a straightforward way, without any self-improvement mechanism beyond the immediate reflection loop. Now imagine we wrap the agent’s logic or key steps in a DSPy program. We can then apply a GEPA-inspired optimization cycle at a higher level: run the agent on a variety of multi-hop questions, have a “critic” (which could be a separate evaluation script or an LLM judge) analyze each full question-answering trajectory, and use those critiques to modify the agent’s prompt or add helpful sub-modules. This essentially adds an outer loop of prompt evolution around the inner agent loop. Strands provides the flexible agent skeleton, and DSPy provides the evolutionary brain that can refine that skeleton’s behavior.
The transitive value of this setup cannot be overstated. Strands Agents by itself gives you a dynamic, tool-using agent. DSPy by itself gives you optimized prompts for modular tasks. When combined, the whole agent becomes self-improving: not in the sense of updating its weights (as in traditional reinforcement learning), but in the sense of continuously honing its strategies. GEPA demonstrated that such prompt-level evolution can yield dramatic improvements in efficiency and performance . By adopting DSPy’s framework, we bring that same dynamic optimization to our agents. It’s a bit like turning a static map into a GPS that recalculates the route based on traffic – the agent can adjust its “instructions” to itself as it encounters new challenges.
To make this more tangible, let’s walk through our running example one last time with AWS Strands + DSPy in the mix. Suppose we build a “Research Assistant” agent with Strands that handles questions requiring multi-hop reasoning. We integrate a DSPy module that defines how the agent should answer questions (this could simply wrap the agent’s main prompt in a DSPy Signature/Module, enabling us to compile it). We then simulate a series of multi-hop QA tasks the agent should solve (maybe drawn from a benchmark like HotpotQA). Initially, we observe some common failure modes: for instance, when a question requires two separate lookups, the agent sometimes stops after one, giving an incomplete answer. We feed these observations to a reflective optimizer. The optimizer uses the agent’s trajectories as data – each trajectory includes the question, the agent’s tool usage (search queries, etc.), the intermediate results, and the final answer. For each, it also knows the correct answer (ground truth) or at least can prompt an evaluator to judge the result. Armed with this, the optimizer might produce reflections like: “On Question 3, the agent failed because it didn’t search for the second entity needed. The prompt doesn’t mention multi-part questions explicitly.” and “On Question 5, the agent’s final answer missed details; perhaps it should be instructed to consolidate information from all sources.” Using these insights (which mirror what a human developer might realize after debugging a few examples), DSPy’s optimizer can modify the agent’s prompt. It might insert a guideline: “For questions with multiple parts, ensure you gather information on each part before answering.” It could also add a couple of one-shot examples into the prompt illustrating the agent reasoning through a two-hop question correctly. The next time we deploy the agent, it performs markedly better – now it reliably does that second lookup and cross-checks the facts, thanks to the evolved prompt. In effect, our Strands agent has learned a new high-level rule (multi-hop questions need multi-hop thinking) without any new code – the learning happened through prompt evolution, exactly as GEPA advocates .
Conclusion: Modular Reflexes for Compound AI Systems
In compound AI systems – whether it’s an LLM agent solving multi-hop questions, a chatbot using tools, or any multi-step workflow – the ability to refine behavior without retraining models is a game-changer. GEPA’s research has shown that letting an AI system reflect in natural language and evolve its own prompts can outperform heavyweight RL approaches, achieving more with less data . DSPy emerges as a practical framework to harness this power. Its modular design, declarative prompt definitions, and built-in optimizers make it feasible to build an AI pipeline once and then continually improve it through feedback loops. The conceptual alignment with GEPA is clear: DSPy’s optimizers simulate and refine execution traces much like GEPA’s reflective prompt evolution does . And DSPy’s ability to integrate multi-step modules resonates strongly with the needs of agentic systems that involve sequences of reasoning and tool use.
For API practitioners and AI engineers, the marriage of DSPy and frameworks like AWS Strands Agents offers a compelling development paradigm. You get the best of both worlds: high-level, model-driven agent orchestration and low-level prompt optimization. Your agents can be both flexible (thanks to Strands’ model-first design that lets the LLM figure out the steps ) and precisely tuned (thanks to DSPy’s targeted prompt tweaking and few-shot bootstrapping ). The result is an AI system that learns to solve tasks better over time by rewriting its own playbook, not unlike a team of experts refining their strategy after each game. It’s a formal approach, grounded in the latest research, but it can also feel a bit magical (and certainly entertaining) to watch an agent improve itself in this way.
As we’ve seen with the multi-hop QA example, a DSPy-optimized agent can start from a reasonable baseline and quickly close the gap to expert-level prompt engineering through automated reflection and iteration. Each mistake it makes today seeds the insight that prevents tomorrow’s mistake. In a world where AI capabilities are increasingly delivered via APIs and composed into larger workflows, DSPy plus GEPA’s insights give us a template for building self-improving, adaptive AI services. Instead of one-off prompt tweaks and endless manual tuning, we get a sustainable loop of feedback-driven enhancement. For anyone building compound AI systems, that means less time fighting prompt syntax and more time delivering robust solutions – your agents won’t just work, they’ll get better with age. By embracing frameworks like DSPy and the lessons from GEPA, we move closer to AI systems that can evolve their strategies on the fly, continuously aligning themselves with the complex tasks we throw at them. And that truly is a new paradigm for AI development.
Sources: